官方微信
登录
注册
搜索
搜索
文章
帖子
用户
免费发布信息
首页
Portal
新闻资讯
论坛
BBS
分类信息
房源中心
租房
跳蚤市场
活动
新闻
加国
大多
美国
环球
经济
时政
娱乐
地产
信息
房源
新盘
家庭旅馆
跳蚤市场
拼车
折扣
机票邮轮
生活服务
社区
城事杂谈
旅游天地
大多生活
房产楼市
北美股票
房东信息
税务理财
健康锻炼
交友征婚
法律求助
加国新闻
大多新闻
美国新闻
环球新闻
经济观察
时政频道
财经资讯
娱乐八卦
生活百态
史海钩沉
健康养生
国际体坛
城事杂谈
大多生活
旅游天地
房产聚焦
税务理财
北美股票
子女教育
房东信息
健康锻炼
移民留学
体育娱乐
婚姻生活
宠物乐园
我爱我家
流行时尚
交友征婚
法律求助
便民信息
黄页
机票邮轮
求职招聘
换汇交易
拼车中心
商家折扣
二手车
非诚勿扰
周边游
扫一扫,关注我们
我的空间
我的消息
我的收藏
我的好友
我的相册
我的道具
帐号设置
退出登录
加国新闻
大多新闻
美国新闻
环球新闻
经济观察
时政频道
财经资讯
娱乐八卦
生活百态
史海钩沉
健康养生
国际体坛
城事杂谈
大多生活
旅游天地
房产聚焦
税务理财
北美股票
子女教育
房东信息
健康锻炼
移民留学
体育娱乐
婚姻生活
宠物乐园
我爱我家
流行时尚
交友征婚
法律求助
便民信息
黄页
机票邮轮
求职招聘
换汇交易
拼车中心
商家折扣
二手车
非诚勿扰
周边游
加国同城
›
首页
›
科技
›
查看内容
英伟达掌握AI时代“摩尔定律”,会加大中美AI差距么(图)
2024-4-18 20:35
|
发布者:
青青草
|
查看:
1
|
评论:0
|
来自: 阿尔法公社
摘要:
当地时间3月18日,英伟达在2024 GTC大会上发布了多款芯片、软件产品。创始人黄仁勋表示:“通用计算已经失去动力,现在我们需要更大的AI模型,更大的GPU,需要将更多GPU堆叠在一起。这不是为了降 ...
当地时间3月18日,英伟达在2024 GTC大会上发布了多款芯片、软件产品。 创始人黄仁勋表示:“通用计算已经失去动力,现在我们需要更大的AI模型,更大的GPU,需要将更多GPU堆叠在一起。这不是为了降低成本,而是为了扩大规模。”
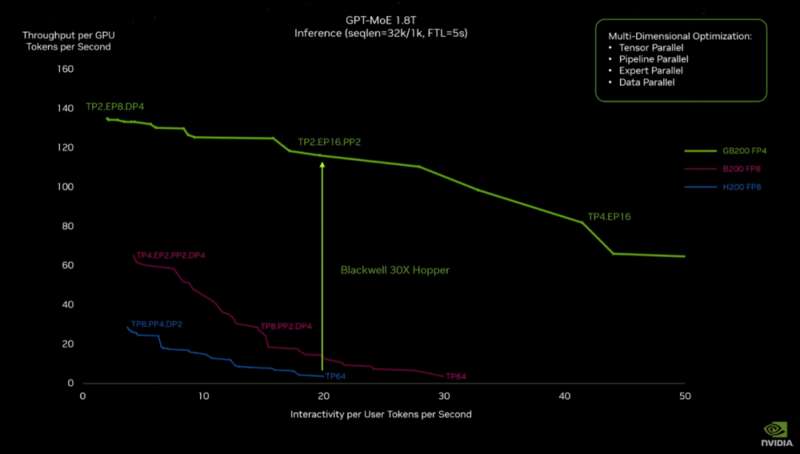
作为GTC大会的核心,英伟达发布了Blackwell GPU,它分为B200和GB200系列,后者集成了1个Grace CPU和2个B200 GPU。 NVIDIA GB200 NVL72大型机架系统使用GB200芯片,搭配NVIDIA BlueField-3数据处理单元、第五代NVLink互联等技术,对比相同数量H100 Tensor核心的系统,在推理上有高达30倍的性能提升,并将成本和能耗降低了25倍。 在AI应用方面,英伟达推出Project GR00T机器人基础模型及Isaac机器人平台的重要更新。
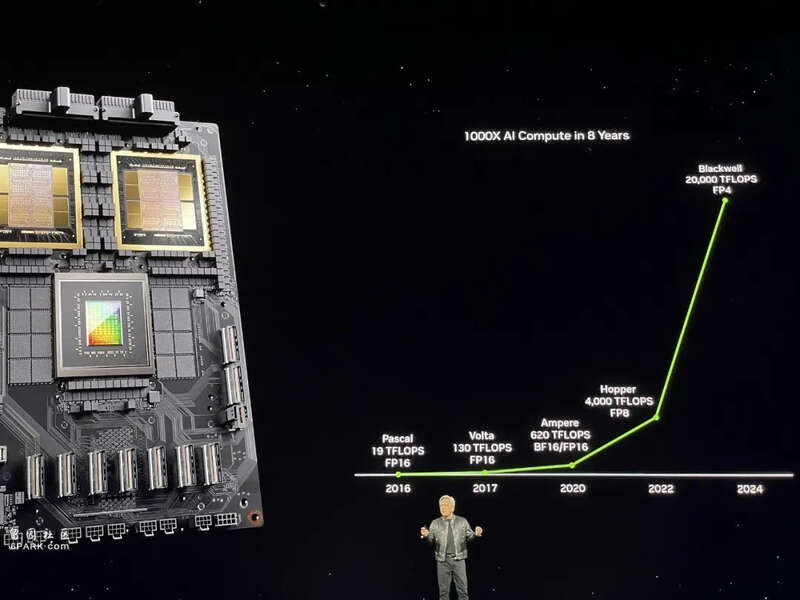
英伟达展示其AI芯片的算力在过去8年里实现了1000倍的增长,这代表AI时代的摩尔定律(算力快速增长,算力成本快速下降)正在形成。
01 实现10万亿参数AI模型的训练和实时推理
在GTC大会上,英伟达不仅发布了算力方面的更新,也介绍了其在应用方面的进展。
1.更强的训练算力,更快、成本更低的推理
Blackwell不仅是一块芯片,也是一个平台。英伟达的目标是让规模达到10万亿参数的AI模型可以轻松训练和实时推理。
它最小的单元是B200,内置2080亿个晶体管,使用定制的4NP TSMC工艺制造,采用Chiplet架构,两个GPU dies通过每秒10TB的芯片到芯片链接连接成一个统一的GPU。 GB200超级芯片则将两个B200 Tensor核心GPU通过每秒900GB的超低功耗NVLink芯片到芯片互连技术与NVIDIA Grace CPU连接。
再往上一层,则是NVIDIA GB200 NVL72,这是一个多节点、液冷的机架系统,它内含36个Grace Blackwell超级芯片,包括72个Blackwell GPU和36个Grace CPU,在NVIDIA BlueField-3数据处理单元的支持下,它能实现云网络加速、可组合存储、零信任安全性以及在超大规模AI云中的GPU计算弹性。 这个系统可以被作为"单个GPU"工作,这时它能提供1.4 exaflops的AI性能和30TB的快速内存。据称,一个GB200 NVL72就最高支持27万亿参数的模型。 最大规模的系统则是DGX SuperPOD,NVIDIA GB200 NVL72是DGX SuperPOD的构建单元,这些系统通过NVIDIA Quantum InfiniBand网络连接,可扩展到数万个GB200超级芯片。 此外,NVIDIA还提供HGX B200服务器板,通过NVLink将八个B200 GPU连接起来,支持基于x86的生成式AI平台。HGX B200通过NVIDIA Quantum-2 InfiniBand和Spectrum-X以太网网络平台支持高达400Gb/s的网络速度。 GB200还将在NVIDIA DGX云上提供给客户,这是一个与AWS、谷歌云和甲骨文云等领先的云服务提供商共同设计的AI平台,为企业开发者提供专用访问权限,以构建和部署先进的生成式AI模型所需的基础设施和软件。 英伟达以实际的模型训练为例,训练一个GPT-MoE-1.8T模型(疑似指GPT-4),此前使用Hopper系列芯片需要8000块GPU训练90天,现在使用GB200训练同样的模型,只需要2000块GPU,能耗也只有之前的四分之一。
由GB200组成的系统,相比相同数量的NVIDIA H100 Tensor核心GPU组成的系统,推理性能提升30倍,成本和能耗降低25倍。
在背后支持这些AI芯片和AI算力系统的是一系列新技术,包括提升性能的第二代Transformer引擎(支持双倍的计算和模型大小)、第五代NVLink(提供了每个GPU1.8TB/s的双向吞吐量);提升可靠性的RAS引擎(使AI算力系统能够连续运行数周甚至数月);以及安全AI(保护AI模型和客户数据)等。 在软件方面,Blackwell产品组合得到NVIDIA AI Enterprise的支持,这是一个端到端的企业级AI操作系统。NVIDIA AI Enterprise包括NVIDIA NIM推理微服务,以及企业可以在NVIDIA加速的云、数据中心和工作站上部署的AI框架、库和工具。NIM推理微服务可对来自英伟达及合作伙伴的数十个AI模型进行优化推理。 综合英伟达在算力方面的创新,我们看到它在AI模型训练和推理方面的显著进步。 在AI的模型训练方面,更强的芯片和更先进的芯片间通讯技术,让英伟达的算力基础设施能够以相对较低的成本训练更大的模型。GPT-4V和Sora代表了生成式AI的未来,即多模态模型和包括视频在内的视觉大模型,英伟达的进步让规模更大、更多模态和更先进的模型成为可能。 在AI推理方面,目前越来越大的模型规模和越来越高的实时性要求,对于推理算力的挑战十分严苛。英伟达的AI算力系统推理性能提升30倍,成本和能耗降低25倍。不仅让大型模型的实时推理成为可能,而且解决了以往的并不算优秀的能效和成本问题。
2.着重发力具身智能
英伟达在GTC大会上公布了一系列应用方面的新成果,例如生物医疗、工业元宇宙、机器人、汽车等领域。其中机器人(具身智能)是它着重发力的方向。 它推出了针对仿生机器人的Project GR00T基础模型及Isaac机器人平台的重要更新。
Project GR00T是面向仿生机器人的通用多模态基础模型,充当机器人的“大脑”,使它们能够学习解决各种任务的技能。 Isaac机器人平台为开发者提供新型机器人训练模拟器、Jetson Thor机器人计算机、生成式AI基础模型,以及CUDA加速的感知与操控库 Isaac机器人平台的客户包括1X、Agility Robotics、Apptronik、Boston Dynamics、Figure AI和XPENG Robotics等领先的仿生机器人公司。 英伟达也涉足了工业机器人和物流机器人。Isaac Manipulator为机械臂提供了最先进的灵巧性和模块化AI能力。它在路径规划上提供了高达80倍的加速,并通过Zero Shot感知(代表成功率和可靠性)提高了效率和吞吐量。其早期生态系统合作伙伴包括安川电机、PickNik Robotics、Solomon、READY Robotics和Franka Robotics。 Isaac Perceptor提供了多摄像头、3D环绕视觉能力,这些能力对于自动搬运机器人特别有用,它帮助ArcBest、比亚迪等在物料处理操作等方面实现新的自动化水平。
02 英伟达算力井喷后,对创业公司有何影响?
在发展方式上,英伟达与OpenAI等公司有明显的不同。 OpenAI以及Anthropic、Meta等公司是以AI模型为核心,然后运营平台和生态;英伟达则以算力为核心,并拓展到软件平台和AI的相关应用。并且在应用方面,它并没有表现出一家垄断的态势,而是与各种行业的合作伙伴共创,其目的是建立一个软硬件结合的庞大生态。 此次英伟达在算力方面的进步,对于AI创业公司们也产生了深刻影响。 对于大模型领域创业公司,例如OpenAI等,这显然是利好,因为他们能以更快的频率,更低的成本训练规模更大,模态更多的模型,并且有机会进一步降低API的价格,扩展客户群体。 对于AI应用领域的创业公司,英伟达不仅将推理算力性能提高了数十倍,而且降低了能耗和成本。这让AI应用公司们能在成本可承担的前提下,拓展业务规模,随着AI算力的进一步增长,未来AI应用公司的运营成本还可能进一步降低。 对于AI芯片领域的创业公司,英伟达的大更新让他们感受到了明显压力,而且英伟达提供的是一套完整的系统,包括算力芯片,芯片间通信技术,打破内存墙的网络芯片等。AI芯片创业公司必须找到自己真正能建立优势的方向,而不是因为英伟达这类巨头的一两次更新就失去存在价值。 中国的AI创业公司,因为各种各样的原因,很难使用最新最强的英伟达AI芯片,作为替代的国产AI芯片在算力和能效比上目前仍有差距,这可能导致专注大模型领域的公司们在模型的规模扩展和迭代速度上与海外的差距拉大。 对于中国的AI应用公司,则仍有机会。因为它们不仅可以用国内的基础模型,也可以用海外的先进开源模型。中国拥有全球顶尖的AI工程师和产品经理,他们打造的产品足可以参与全球竞争,这让AI应用公司们进可以开拓海外市场,还有足够庞大的国内市场做基本盘,AI时代的字节跳动、米哈游很可能在它们中间产生。
路过
雷人
握手
鲜花
鸡蛋
分享
邀请
上一篇:
从缺芯到缺电?美国能源巨头:AI将令电力需求飙升(图)
下一篇:
日多地水体和居民血液检出有害物 政府启动相关研究(图)
最新评论
评论
相关分类
新闻资讯
分类信息
地产
健康
活动
移民
历史
军事
生活
科技
就业
旅游
文化
测试
图文热点
出抽油烟机
今天起!多伦多High Park樱花全部盛放!全
热门推荐
出抽油烟机
跳个蹦蹦床都这么有范
大河向东流啊,恩恩爱爱纤绳荡悠悠
第一次看见猪打哈欠
八九十年代,中国大地上驰骋的12款老车,开
2024 年,18 张最美丽的婚礼照片
联系客服
关注微信
返回顶部
点击联系客服
在线时间:8:30-17:00
电子邮件
kefu@58.ca
扫一扫,关注我们
下载APP客户端